


What’s the Real Difference?
Picture this. You’re a CTO or engineering lead, and someone on your team tells you they’re “using AI to write code.” Maybe you already knew that. Maybe you encouraged it. Now a board member or a client asks a simple follow-up: how do you know it’s safe to ship?
That’s the question most companies can’t answer cleanly right now — not because they haven’t thought about it, but because “using AI to write code” covers a spectrum so wide it spans everything from building a weekend tool with zero review to Stripe shipping 1,300 AI-written pull requests a week through a six-layer engineering system with automated testing, CI pipelines, and mandatory human review before anything merges.
One of these is fine for your production codebase. One is not. The terms the industry has landed on to describe them are agentic engineering and vibe coding — and the distinction between them has real consequences, not just semantic ones.
The Short Answer
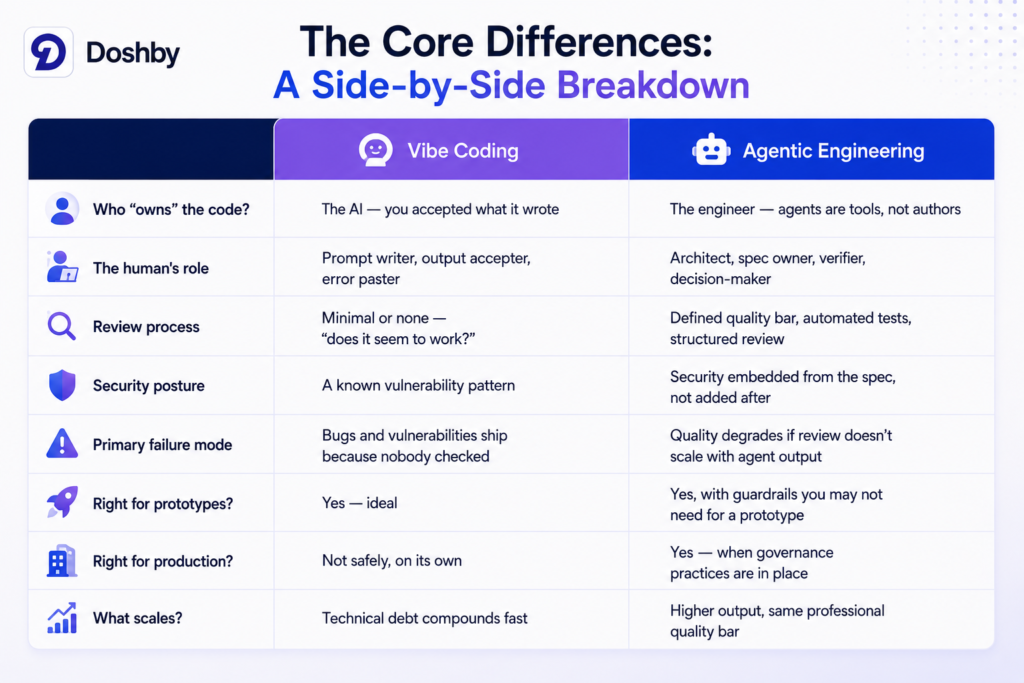
Vibe coding means directing an AI to write code and accepting the output with minimal or no review — a fast, creative workflow that works well for prototypes and personal projects, but breaks down when real users, real data, and real security requirements enter the picture. Agentic engineering means using those same AI coding agents under a structure of human oversight: you own the spec, you define what “correct” looks like, and you verify the output before it ships.
Both use AI agents to produce code. The difference is who stays accountable for what those agents produce — and what happens when they get it wrong. If you want a deeper look at what agentic engineering means as a standalone concept, which covers it from the ground up. This one is about how the two approaches differ, where each belongs, and how to tell which one your team is actually doing right now.
Where Each Term Came From
Andrej Karpathy — co-founder of OpenAI, former head of AI at Tesla; coined “vibe coding” in a February 2025 post describing the experience of having a natural-language conversation with an AI and letting it build the application without reviewing what it wrote. The phrase went viral, spread far beyond its original meaning, and within a year had become what Google engineer Addy Osmani described as a “suitcase term” — used to describe everything from a weekend hack to a disciplined professional workflow. These are fundamentally different activities, and conflating them was causing real confusion, and real damage.
At Sequoia’s AI Ascent 2026 event, Karpathy drew the line. The term he introduced for the disciplined end of the spectrum “agentic engineering” landed in a way that Willison’s earlier attempt (“vibe engineering”) hadn’t, partly because it dropped “vibe” entirely and made clear this was a professional practice. IBM had published its own explainer on the term within weeks. The debate has since moved from whether the distinction exists to exactly where the line sits in practice.
Where Vibe Coding Actually Works
Vibe coding isn’t a mistake. In the right context, it’s exactly the right tool. Simon Willison, one of the clearest voices on this distinction, put the appropriate use case plainly: vibe coding is for situations where bugs only hurt you. Personal scripts and one-off tools you’re the only user of. Prototypes and hackathon demos where the goal is something working by Sunday, not a system someone will maintain. Learning projects where the AI’s output is the thing you’re studying, not the thing you’re shipping.
The common thread across all of these is low stakes and no downstream consequences. If you’re building something for yourself, where you can regenerate it if it breaks and nobody else is affected, the absence of rigorous review isn’t a risk — it’s a reasonable trade-off for speed.
Where Vibe Coding Breaks Down
The failure mode isn’t mysterious. When code moves from a prototype into production and into a system with real users, real data, and real consequences for failures then, the absence of structured review becomes structural risk, not just technical debt.
The security data tells that story consistently. Veracode’s 2025 GenAI Code Security Report, testing more than 100 language models across four programming languages, found that AI-generated code introduced security vulnerabilities at 2.74 times the rate of human-written code. A separate December 2025 study of open-source repositories, cited by IBM, found AI-generated code introduced security vulnerabilities in 45% of development tasks. GitGuardian’s State of Secrets Sprawl 2026 report (March 2026) documented a 34% year-over-year increase in hardcoded secrets exposed in public GitHub commits during 2025 — the largest single-year jump on record — with AI-assisted commits showing roughly double the baseline credential exposure rate.
It is worth framing those numbers honestly: they describe code accepted without adequate review, not AI-generated code per se. The vulnerability is in the process, not the model. But that framing is also the entire argument for agentic engineering over vibe coding in production.
The cost of skipping that review is no longer theoretical. In January 2026, “Moltbook” an AI-built social network whose founder had written zero lines of code himself exposed 1.5 million API authentication tokens and 35,000 email addresses within 72 hours of launch. The vulnerability wasn’t sophisticated: it was a missing access control that a standard security review would have caught before launch. That same month, separate documented incidents involving unreviewed AI-generated code included an inverted access control logic flaw affecting 170 live applications, a platform-wide authentication bypass, and a case where an AI agent wiped a production database during an explicit code freeze.
At the enterprise scale, Amazon’s experience in early 2026 is the clearest illustration of the same failure mode with more zeros. After a string of incidents that includs one in which its Q coding assistant was named as a contributing factor in an outage that disrupted millions of customer orders, Amazon’s SVP of e-commerce Dave Treadwell rolled out a 90-day code safety reset across 335 Tier-1 systems: mandatory two-person review for every change, formal documentation requirements, and leadership audits. He called it “controlled friction” deliberately slowing deployment to catch what the pace of AI output had started to outrun. Amazon hadn’t made a mistake by using AI to write code. It had made a mistake by not scaling its review processes to match.
What Agentic Engineering Looks Like When It Works
If you want to see what the disciplined version looks like at scale, Stripe’s internal “Minions” system is the reference case the engineering community keeps returning to.
Every week, Stripe merges approximately 1,300 pull requests that contain no human-written code. Not a single line. An engineer sends a message in Slack — a fix, a refactor, a dependency update — and a Minion agent spins up in an isolated cloud machine in under ten seconds, reads the relevant documentation, searches the codebase, writes the code, runs tests, pushes to CI, and submits a pull request. The engineer comes back to a finished PR that has already passed automated checks and is ready for human review.
That last phrase is the critical detail. All 1,300 PRs are still reviewed by engineers before they merge. The human role has shifted from writing code to reviewing it, but the review has not disappeared. The system works because Stripe built the infrastructure first: robust CI pipelines, extensive test coverage, blue-green deployments for quick rollbacks, and structured blueprints that define each task type explicitly so agents aren’t guessing at scope or constraints. The lesson from Stripe’s experience isn’t that they found a smarter model. It’s that they built the engineering fundamentals that were always supposed to matter before they handed the execution to agents.
Wes McKinney, the creator of pandas and co-creator of Apache Arrow, made the same point from a different angle at AI Council 2026: “When code is free, saying no is our last defence.” Every feature an agent produces is cheap to create and expensive to maintain. Each one adds surface area for bugs, confusion, and future agent mistakes. Agentic engineering is, among other things, a discipline for knowing what to say no to — and having the engineering judgment to tell the difference between an agent that got it right and one that got it plausibly wrong.
FURTHER READING
➤ How AI Call Agents Actually Work: An ElevenLabs Case Study
How to Tell Which One Your Team Is Actually Doing
The most useful thing about this distinction is that it’s practical, not philosophical. Five questions cut through the tool names and buzzwords:
1. Does someone own a spec before agents start writing? In agentic engineering, the requirements, constraints, and definition of “correct” exist before a single line is generated. If the spec is vague, emergent, or defined by whatever the AI produces first, the verification step has nowhere to anchor itself.
2. Is there a defined quality bar, or just “does it run?” Working code and secure, maintainable code are not the same thing. Carnegie Mellon University research found that while 61% of AI-generated code functions correctly, only around 10% passes security review. Agentic engineering applies a quality bar beyond functional correctness; vibe coding usually stops at the surface check.
3. Who reviews the output, and what are they actually looking for? Stripe’s engineers review PRs. Amazon’s new policy requires two engineers to approve every change. If the answer to “who reviews this?” is “nobody formally,” that is a clear signal about which side of the line your workflow sits on.
4. Does your review process scale with how fast agents can produce code? This is the Amazon problem, stated plainly. The failure wasn’t adopting AI, it was that review infrastructure stayed at the old pace while AI output multiplied. If your agents are producing ten times the code, your verification needs to have kept up.
5. If something ships with a critical bug, can you explain exactly what was reviewed and by whom? Agentic engineering leaves a traceable audit trail from spec to PR to review to merge. Vibe coding often doesn’t. That audit trail is not a bureaucratic nicety — it’s what lets you catch issues before they reach users, and understand them after they do.
If you answered “not confidently” to two or more of these, the honest description of what your team is doing is closer to vibe coding than agentic engineering, regardless of which tools you’ve licensed or what the vendor called the workflow.
Agentic Engineering vs. Vibe Coding FAQs
Vibe coding means having an AI write code and accepting the result with minimal review. Agentic engineering means having an AI write code under a structure where a human engineer owns the spec, defines what “correct” looks like, and verifies the output before it ships. Same tools — fundamentally different process and accountability.
No. For prototypes, learning projects, personal tools, and anything where the only person affected by a bug is you, vibe coding is often the right call. It becomes a problem when those habits are carried into production systems that other people depend on.
Simon Willison has admitted that the line blurs in his own production work as agents get more reliable. His answer isn’t that experienced engineers should vibe code freely — it’s that the engineering judgment you bring is what makes the output safe to trust. Without that underlying expertise, accepting AI output without review is genuinely risky regardless of the model.
“AI-assisted coding” describes a tool relationship. “Agentic engineering” describes a practice: agents don’t just assist, they execute multi-step workflows autonomously, reading codebases, running tests, and iterating on failures without turn-by-turn guidance. The “engineering” half is the part that says a human is still accountable for what those agents produce.
Not in the way the question usually implies. It means the same number of experienced developers can credibly own more. The demand for engineers who understand architecture, security, and verification is rising — what changes is how much time they spend on the parts that agents handle well, and how much they spend on the parts that still require human judgment.
Vibe coding and agentic engineering both involve AI agents writing and executing code. Traditional RPA automates fixed, rule-based processes without generating new code. The governance principles overlap — human oversight, defined scope, audit trails — but the tools and capabilities are different. We’ll cover the full AI agents vs. RPA vs. workflow automation comparison in an upcoming post.
Simon Willison described this distinction in the most memorable way during a podcast conversation earlier this year. He said: he can plumb his own house if he watches enough YouTube videos on plumbing but he would rather hire a plumber.
That is what agentic engineering is; not replacing the plumber with a robot, but giving an expert plumber tools that let them do in hours what used to take days, while staying the person accountable for the quality of what is installed. Vibe coding is watching the YouTube video and hoping for the best. That is perfectly fine for a leaky tap in your own home. It is not fine for the water mains.
The difference between the two approaches is not really about which AI tools you have licensed. It is about whether the humans in your engineering process have stayed accountable for the output or whether “the AI wrote it” has quietly become an explanation that stops conversations instead of starting them.
At Doshby, agentic engineering is not a service we sell. It is how we work. If you are trying to understand what a responsible, production-grade AI-assisted development process looks like inside your organization or whether the one you have now would survive real scrutiny kindly get in touch.


